DeepSeek Unleashed: Democratizing Energy-Efficient Generative AI for a Sustainable Future

The emergence of DeepSeek's innovative AI model has sent shockwaves through the tech industry, and the rapid evolution of open-source large language models is driving a global democratization of AI technology. This breakthrough challenges long-held assumptions about the computational resources required for advanced AI systems and could have far-reaching implications for the future of AI development and its climate impact.
This blog post examines key insights from the DeepSeek models, highlighting how they are potentially reducing the energy footprint of generative AI. At a high level, we see this development accelerating the adoption of generative AI and associated productivity gains that are net positive for the climate when executed at a lower energy footprint. It also opens up the possibility that innovations in training and inference (when they are used) of Large Language Models (LLMs) can come from smaller startups, instead of just the hyperscalers. This expands the investable universe for CLAI Ventures in startups driving energy efficiency gains in generative AI.
A Timeline of Events
While most of the attention has focused on the DeepSeek R1 model released on January 22, 2025, much of the technical breakthrough was achieved in the DeepSeek V3 pretrained model that came out on December 27, 2024. R1 took the V3 model and applied reinforcement learning rather than supervised finetuning as per industry standard. Reinforcement learning removes the need to have a large labeled dataset of desired model outputs.
What was impressive was that DeepSeek was achieved with a small team. Disclosed in the V3 technical paper are 139 engineers and researchers including the founder, Liang Wenfeng, who worked on building the model. At the time OpenAI’s R&D team was ~1200 employees, and Anthropic’s was 500+.
On January 29, 2025, in Facebook’s 4Q2024 investor call analysts ask Mark Zuckerberg to comment on DeepSeek on two separate instances, to which he responds: “I also just think in light of some of the recent news, the new competitor DeepSeek from China, I think it also just puts -- it’s one of the things that we’re talking about is there’s going to be an open source standard globally.”
Mark’s comments encapsulate the most significant takeaway from the call: the ongoing democratization of access to LLMs is reshaping the industry.
Source: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learning (https://arxiv.org/pdf/2501.12948)
DeepSeek's Technical Innovations
DeepSeek has achieved remarkable efficiency gains through simultaneous advancements on many existing ideas.
While it is common to use fewer decimal places in a trained model during inference (a technique called “quantization”), DeepSeek was able to dramatically reduce memory requirements by utilizing a mixed precision data format that allows lower and higher precision numbers as necessary.
The DeepSeek team improved the key-value cache introduced in the original Transformer paper through a technique called multi-head latent attention which allows for faster inference that they first invented in DeepSeek v2.
They also innovated upon an existing approach called Mixture-of-Experts where specialized "experts" are only activated when needed, significantly reducing computational load compared to activating the entire model at once. DeepSeek improves upon this by load balancing across the experts during training time in order to encourage the most useful experts to get developed.
The team used a technique called multi-token processing that was published by other researchers in 2024 that allows the model to read and process entire phrases at once, greatly increasing speed while maintaining high accuracy.
These innovations combined have resulted in staggering efficiency improvements, with training costs reduced from “few $10M's to train” (per Anthropic on their Claude 3.5 Sonnet cost) to approximately $5M.
See our technical notes below for more details.
Climate Implications
By requiring fewer computational resources, DeepSeek's model could substantially decrease the energy demands of generative AI training and deployment. Ultimately, DeepSeek's approach could offer a path towards more environmentally friendly AI scaling, addressing concerns about the growing carbon footprint of generative AI technologies. Alternatively, it could result in a lower barrier to entry for enhancing pretrained models, such that more viable entrants drive up the total energy used.
Industry Disruption
DeepSeek's innovations have the potential to reshape the AI industry landscape. Lower hardware requirements and costs could make AI development more accessible to a wider range of organizations and researchers, democratizing AI development. Reduced barriers to entry may lead to a more diverse and competitive AI ecosystem.
DeepSeek has highlighted inefficiencies that established players will correct, and the curve will be shifted forward. Per Dario Amodei, CEO of Anthropic, “We’re therefore at an interesting ‘crossover point’, where it is temporarily the case that several companies can produce good reasoning models. This will rapidly cease to be true as everyone moves further up the scaling curve on these models.”
Cautionary Notes
While the potential benefits of DeepSeek's approach are exciting, some experts urge caution. The resulting unfettered proliferation of AI technology across various industries could potentially negate the energy efficiency gains (Jevon’s paradox cited by Satya Nadella on X).
Also, an MIT Tech Review article and a LinkedIn post by Scott Chamberlin argue that claims of reduced compute and energy demands for DeepSeek-type models may be overblown, especially during inference. When comparing Llama 3.3 70B to DeepSeek R1 70B on a real-world inference test suite, the two models showed approximately the same energy efficiency (tokens per Watt-second). Due to DeepSeek R1 generating significantly longer outputs, it resulted in 87% more total energy consumption compared to Llama 3.3 on the same set of prompts. While the jury is still out there, there is reason to believe that over time, inference will constitute the bulk of energy and computational usage in the future, even if training efficiency improves as with DeepSeek.
Implications for CLAI Ventures
The DeepSeek breakthrough aligns well with CLAI Ventures' investment thesis and opens up new opportunities. Current cost of AI on cashburn, anecdotally heard from many YC companies, is as high as $500k/mo. Lower cost structures are likely to drive increased AI adoption and startup creation, expanding the pool of investment opportunities. Open source developments like this bode well for our investments in AI applications that optimize renewable resources, improve weather prediction, and enhance industrial processes.
Additionally, DeepSeek unlocks an investment space for CLAI Ventures focused on startups that drive energy efficiency in generative AI. We anticipate that future innovations in both training and inference will come from agile, smaller teams—not just hyperscalers. These emerging disruptors present a compelling opportunity for us!
Technical Notes:
DeepSeek V3 came out on Dec 27, 2024 (https://arxiv.org/pdf/2412.19437v1)
The key contribution of this paper is the introduction of DeepSeek-V3, a highly efficient and powerful Mixture-of-Experts (MoE) language model that achieves state-of-the-art performance among open-source models while significantly reducing training costs and complexity. The model's innovative architecture, which includes Multi-head Latent Attention (MLA) and an auxiliary-loss-free load balancing strategy, allows it to activate only 37B of its 671B total parameters per token, resulting in efficient inference and training. DeepSeek-V3 demonstrates that it's possible to create a model that rivals closed-source leaders like GPT-4 and Claude in performance across various benchmarks, particularly excelling in coding and mathematical reasoning tasks, while requiring only 2.788M H800 GPU hours (approximately $5.576M) for full training. This achievement challenges the notion that state-of-the-art AI models necessarily require massive computational resources and budgets, potentially democratizing access to advanced AI capabilities.
Here are the main points of the DeepSeek-V3 paper:
DeepSeek-V3, is a powerful Mixture-of-Experts (MoE) language model with 671B total parameters, of which 37B are activated per token.
DeepSeek-V3 utilizes Multi-head Latent Attention (MLA) and DeepSeekMoE architectures for efficient inference and cost-effective training
Auxiliary-Loss-Free Load Balancing: DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing, minimizing performance degradation typically associated with encouraging balanced expert usage.
Multi-Token Prediction Training: The model employs a multi-token prediction training objective, which improves overall performance on evaluation benchmarks.
Extensive Pre-training: DeepSeek-V3 is pre-trained on a massive dataset of 14.8 trillion high-quality and diverse tokens.
Post-Training Refinement: The pre-trained model undergoes Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to align with human preferences and enhance its capabilities. This includes distilling reasoning capabilities from the DeepSeek-R1 series.
8-bit Floating Point (FP8) Mixed Precision Training: The paper introduces and validates an FP8 mixed precision training framework on a large-scale model, achieving accelerated training and reduced GPU memory usage.
Economical Training Costs: Despite its impressive performance, DeepSeek-V3 required only 2.788M H800 GPU hours (approximately $5.576M) for its full training.
Knowledge Distillation: The researchers used a novel method to transfer reasoning abilities from DeepSeek-R1 models (specifically long-Chain-of-Thought models) into DeepSeek-V3, enhancing its reasoning performance while maintaining control over output style and length.
State-of-the-Art Performance: DeepSeek-V3 achieves state-of-the-art performance on various benchmarks among open-source models, demonstrating its capabilities in knowledge, code, math, and reasoning. It performs competitively with leading closed-source models like GPT-4o and Claude-3.5-Sonnet. Specifically, it excels in coding competition benchmarks and performs strongly in mathematical reasoning.
DeepSeek R1 came out on Jan 22, 2025 (https://arxiv.org/pdf/2501.12948)
Key contributions include demonstrating that LLMs can develop reasoning skills through pure RL without supervised fine-tuning, introducing a pipeline for developing DeepSeek-R1, and showing that reasoning patterns of larger models can be effectively distilled into smaller ones.
The key points of the DeepSeek-R1 paper are:
Introduction of two new reasoning models: DeepSeek-R1-Zero, trained using large-scale reinforcement learning (RL) without supervised fine-tuning, and DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL.
Demonstration that powerful reasoning abilities can emerge naturally through RL without relying on supervised data. This is a key finding and major contribution of the paper.
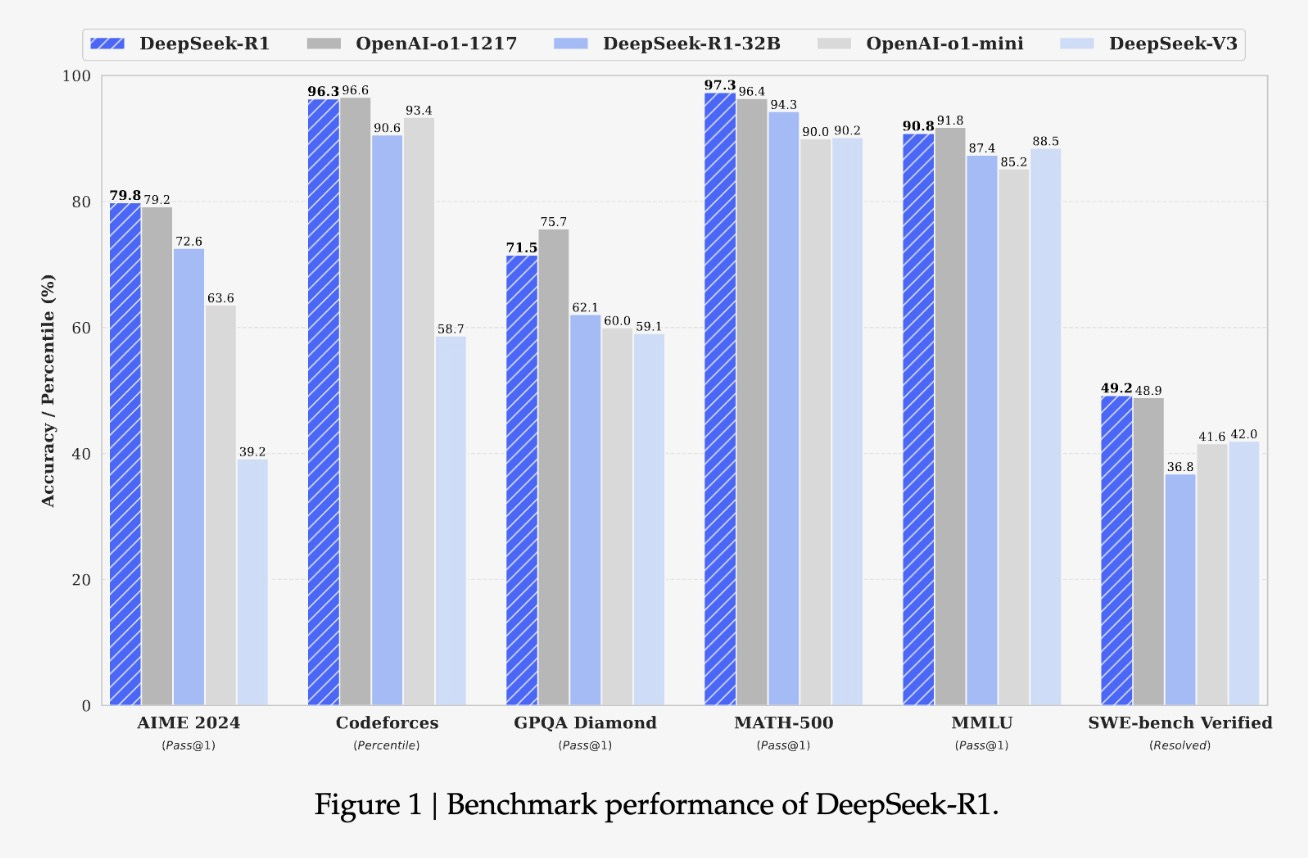
The models achieve competitive performance, with DeepSeek-R1 performing comparably to OpenAI-o1-1217 on reasoning tasks.
The paper explores distilling the reasoning capabilities of DeepSeek-R1 into smaller, dense models (ranging from 1.5B to 70B parameters) based on Qwen and Llama architectures. These distilled models perform very well on benchmarks and are open-sourced.
Evaluation results show strong performance on various tasks, including mathematical reasoning (AIME 2024, MATH-500), code competitions (Codeforces), and knowledge-based benchmarks (MMLU, GPQA Diamond).
The paper highlights the potential of RL in developing reasoning abilities in LLMs, the benefits of a multi-stage training pipeline, and the effectiveness of distillation for creating smaller, high-performing reasoning models.